DTSync: bidirectional directory synchronisation between any number of replicas
For years I've been using Unison and it has served me very well. It is a reliable piece of software with many, many configuration options. But not without it's limitations. So I wrote my own synchronization program DTSync.
The limitations of Unison I run into are:
- It only [synchronizes two replicas] (http://www.cis.upenn.edu/~bcpierce/unison/download/releases/stable/unison-manual.html#usingmultiple). You can of course synchronize more than two replicas but without special precautions this causes many false positives in it's conflict detection algorithm. Unfortunately this is not easily fixable.
- It depends on the hostname and path for unique identification. Re-scanning big media libraries takes a lot of time and needs to be done for each replica pair (on both replicas). With 5 replicas this is a lot of work. Changing hostnames and moving directories is thus something I avoid.
- The UI, while it works well, does have it's limitations. And the command line interface is barely usable when a sync has many changes.
- Synchronization of a replica pair always needs to be started from the same host, as the synchronization state is stored there.
- It does not detect moved files or directories.
The main problem I ran into was the first one, and it turns out it is the most difficult one of them all. Synchronizing more than two replicas is a very difficult problem. I will describe the exact algorithm in a future blog post (update: here it is), but let's say it isn't easy. Furthermore, detecting moved files and directories reliably is much harder than it sounds and impossible (without heuristics) on some filesystems like FAT.
So I started writing my own program. Actually, this is about the sixth time I tried writing this program, all previous versions had some issues here and there that I discovered only too late, when the design was quite fixed and hard to change. New insights usually come while writing a program. Additionally, with each new try there were more features I tried to fit in so it was a moving target.
The reason this version now actually works is that I intentionally left out some harder to implement features. I set out to built a Unison clone with only one extra feature: distributed synchronization. The result is DTSync: distributed tree sync. I also added a GTK3 interface for it to make working with it much easier. Other interfaces (e.g. Qt) can be added easily.
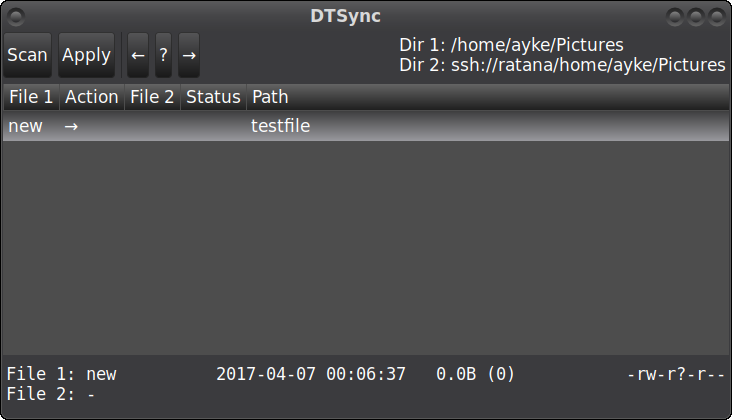
I have written DTSync in such a way that the algorithm itself and the file/directory/ssh parts of it are mostly separated. It should be possible to use it for any other type of synchronization (e.g. browser bookmarks). But still, it's hard to write such decoupled code when there's only one user of the library and with a single goal in mind (directory synchronization).
Downloading
DTSync is written in Go and downloading/compiling it is quite easy once you have installed the official toolchan. You also need the librsync-dev package.
$ go get github.com/aykevl/dtsync/dtsync
You can run dtsync directly once installed (it will be located at $HOME/bin/dtsync), or start the graphical interface using python3 $HOME/src/dtsync/gtk/dtsync.py <path1> <path2>. I hope that providing the paths won't be necessary in a future version, once profiles have been implemented.
Limitations of DTSync
DTSync isn't finished. I use it quite often, but still use Unison a lot for things I haven't yet implemented (mainly the lack of profiles / configuration files and some missing features). I do use it as the standard synchronization tool for my photo library and my music library. So far it works really well.
- It is very much beta software. There are still bugs that really shouldn't be there, though I am not aware of any issues that eat your data.
- It is not very flexible. It has a rudimentary support for excluding and including paths, but it needs some form of sync profiles and many more options.
- The UI (both the command line and the GTK3 interface) are quite limited. They need to have many more options, and the GUI must be able to be used without ever touching the command line (without path arguments).
- Hashing can probably be a lot faster. Right now I'm using blake2b which is very fast, but it is very hard to beat dedicated CPU instructions for SHA2. Unfortunately, the hash needs to be the same on each replica so can't be easily changed.
- Other performance improvements. For example, copying many files is slow over a network link with high latency, and the status is saved in a plain text file which is easy for debugging but is not so efficient to parse.
- Partial synchronizations (when some files are excluded) result in false positives, as the sync cannot be marked "completed".
- Detecting moved files and directories is not yet implemented. I hope to be able to implement it one day, but because of too much bikeshedding in the Linux kernel it takes a while. The necessary syscall should be merged soon, though.
Of course, you can help improve it! The source code is all available on GitHub under a BSD-like license.